Apple、限られたメモリで効率的な大規模言語モデル推論を行う方法を開発
※本サイトは、アフィリエイト広告および広告による収益を得て運営しています。購入により売上の一部が本サイトに還元されることがあります。
LLM in a flash: Efficient Large Language Model Inference with Limited Memory
AppleのMachine Learning Researchは、arXivに「LLM in a flash: Efficient Large Language Model Inference with Limited Memory」を投稿しています。
大規模言語モデル(LLM)は、現代の自然言語処理の中心的存在であり、様々なタスクにおいて卓越した性能を発揮します。しかし、その集中的な計算とメモリ要件は、特にDRAM容量が限られたデバイスにとって課題となります。
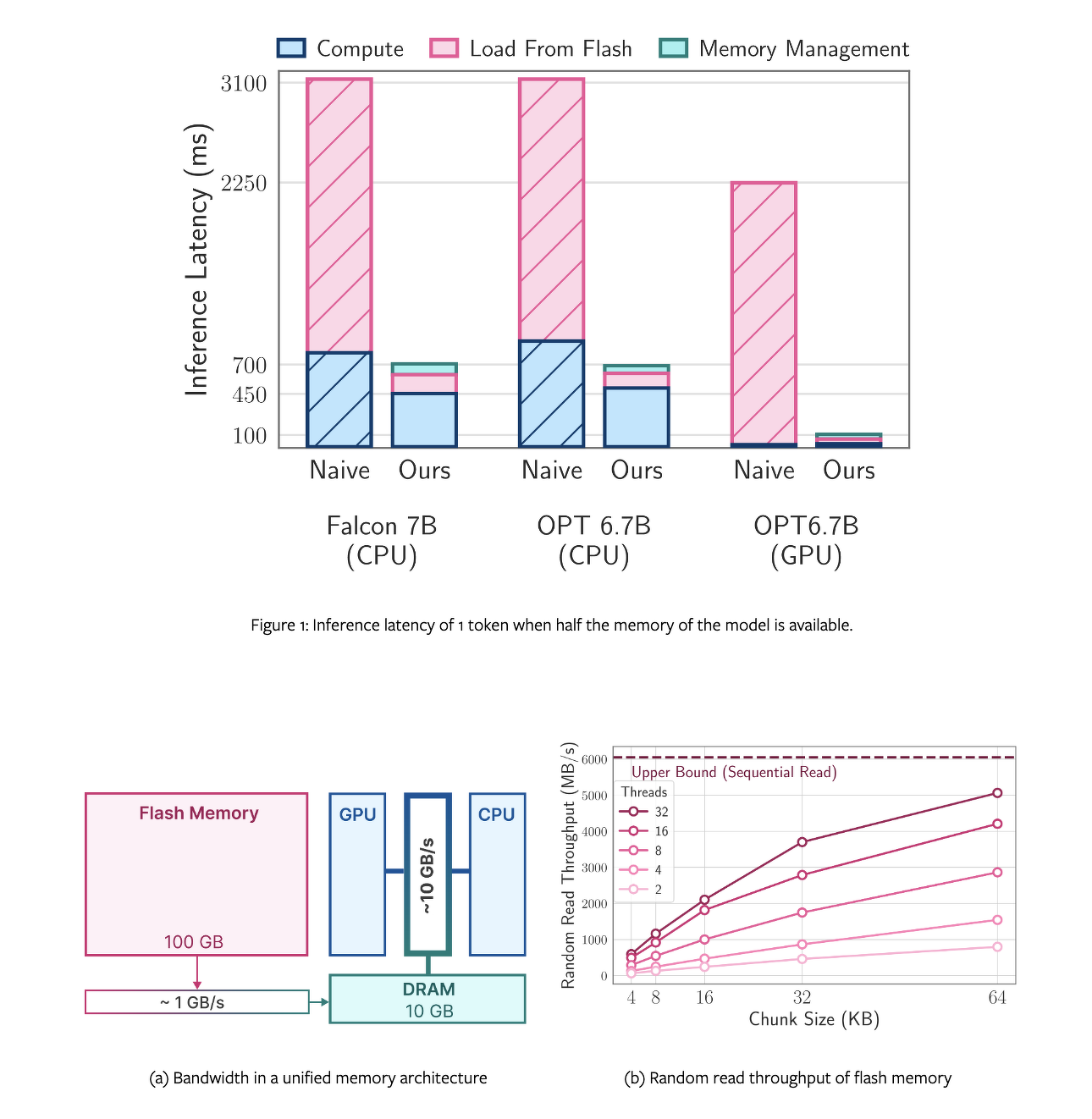
この論文では、モデルのパラメータをフラッシュメモリに保存し、必要に応じてDRAMに取り込むことで、利用可能なDRAM容量を超えるLLMを効率的に実行するという課題に取り組みむと説明しています。
Appleの手法では、フラッシュメモリの動作に調和した推論コストモデルを構築し、フラッシュから転送されるデータ量の削減と、より大きく連続したチャンクでのデータ読み出しという2つの重要な領域での最適化を導きく方法だそうです。
このフラッシュ・メモリ情報に基づくフレームワークの中で、2つの主要なテクニックを紹介するとして、第1に「ウィンドウ化」は、以前に活性化されたニューロンを再利用することにより、戦略的にデータ転送を削減します。
第2に「行-列バンドル」は、フラッシュメモリのシーケンシャルなデータアクセスの強みに合わせて、フラッシュメモリから読み出すデータチャンクのサイズを大きくします。
これらの方法を組み合わせることで、利用可能なDRAMサイズの2倍までモデルを実行することが可能になり、CPUとGPUのナイーブローディングアプローチと比較して、それぞれ4~5倍、20~25倍の推論速度が向上すると説明しています。
スパース性認識、文脈適応型ローディング、ハードウェア指向設計の統合は、限られたメモリしか持たないデバイス上でのLLMの効果的な推論への道を開くと説明しています。