WWDC24:機械学習とAIモデルをAppleシリコンに統合
※本サイトは、アフィリエイト広告および広告による収益を得て運営しています。購入により売上の一部が本サイトに還元されることがあります。

機械学習とAIモデルをAppleシリコンに統合
Appleが、WWDC24において「機械学習とAIモデルをAppleシリコンに統合」を公開しています。
AppleのCore MLチームのエンジニアQiqi Ziao氏は、Core ML Toolsに加えられたいくつかのエキサイティングなアップデートについてお話しします。これらのアップデートは、機械学習やAIのモデルをApple Siliconでより良く活用するのに役立ちます。モデルデプロイのワークフローには3つの重要な段階があります。
私は準備段階に焦点を当て、多くの最適化を共有し、デバイス上でモデルを最も効率的に実行するための機能が含まれていることを確認します。このセッションでは、あなたがすでに機械学習モデルを持っていると仮定します。このモデルは、事前に訓練されたもの、微調整されたもの、あるいはゼロから訓練されたものである可能性があります。
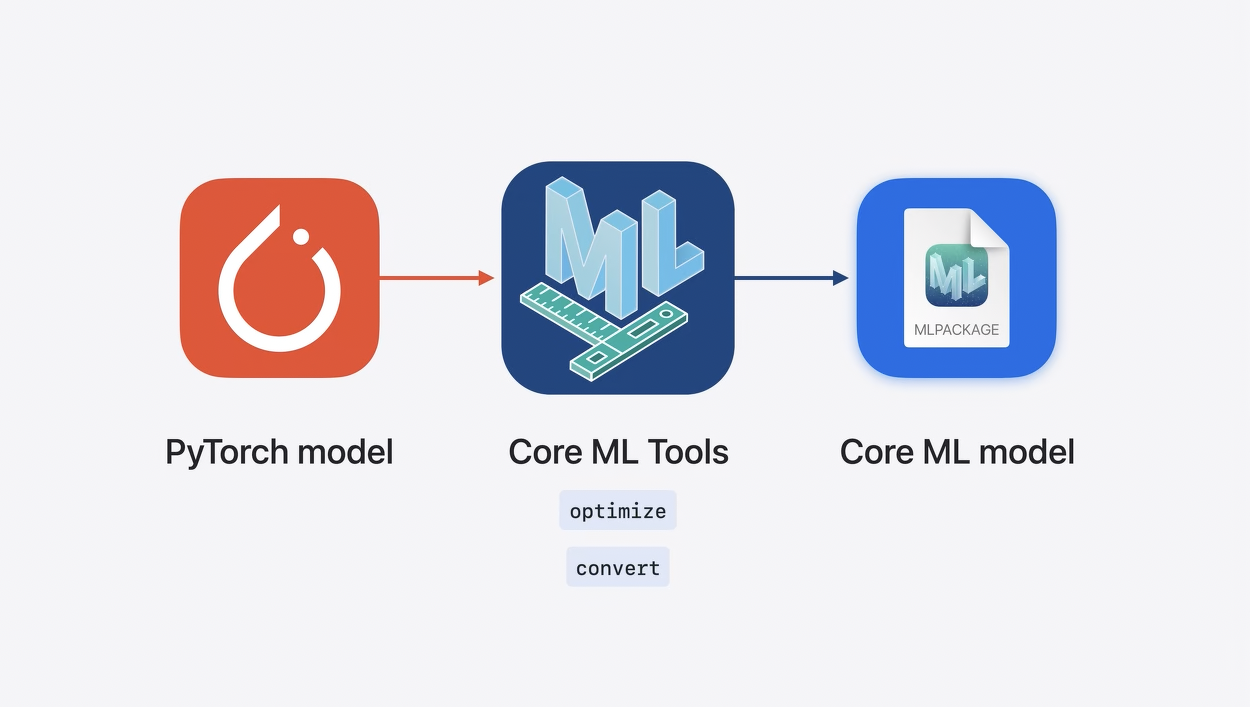
Core ML Tools
Core ML ToolsはオープンソースのPythonパッケージで、Appleのフレームワークで使えるようにモデルを最適化・変換するユーティリティが含まれています。
PyTorch(パイトーチ)で作成したモデルをCore ML形式に変換し、Apple Siliconでの実行に最適化することができます。
Apple Siliconの統合メモリ、CPU、GPU、Neural Engineは、デバイス上の機械学習ワークロードに低レイテンシーと効率的な計算を提供します。
デフォルトでは、モデルをCore MLフォーマットに変換し、推論にAppleのフレームワークを使用するだけで、アプリケーションはApple Siliconのパワーを活用できます。
Apple SiliconはAppleのすべてのプラットフォームに対応していますが、それぞれに独自の特性と強みがあります。
ターゲットとするプラットフォームやデバイスで利用可能なストレージ、メモリ、コンピューティングの組み合わせを考慮する必要があります。
これらの属性は、ユースケースに必要なモデルのサイズ、精度、レイテンシーに合わせる必要があります。
モデル準備の一環として、オプションを検討し、様々な最適化を適用して、最適な配置を見つけます。その方法を一緒に探ってみましょう。
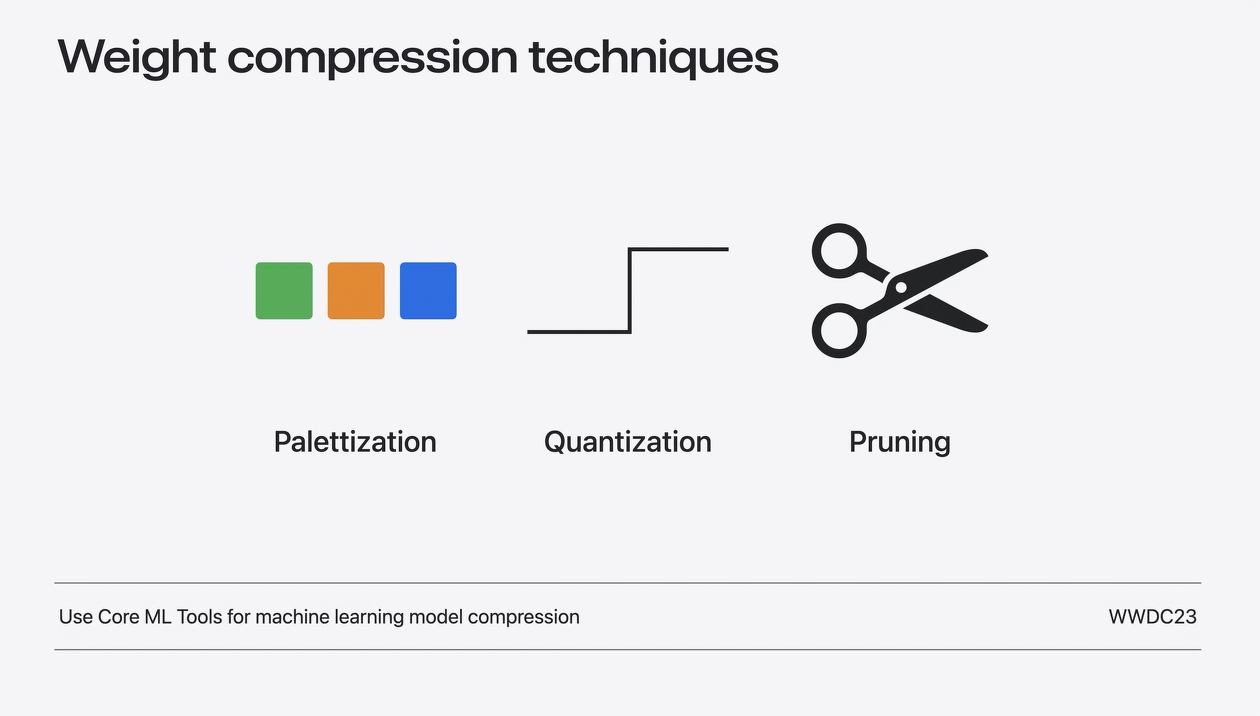
昨年導入されたウェイト圧縮技術
まず、昨年導入されたウェイト圧縮技術を振り返ってみよう。最初のテクニックはpalettizationと呼ばれるもので、パレット化では、似たような値を持つ重みはクラスタ化され、クラスタのセントロイドの値を使って表現されます。
クラスタの中心はルックアップテーブルに格納されます。ルックアップテーブルへのNビットのインデックスマップが圧縮された重みになります。
この例では、重みは2ビットに圧縮されています。
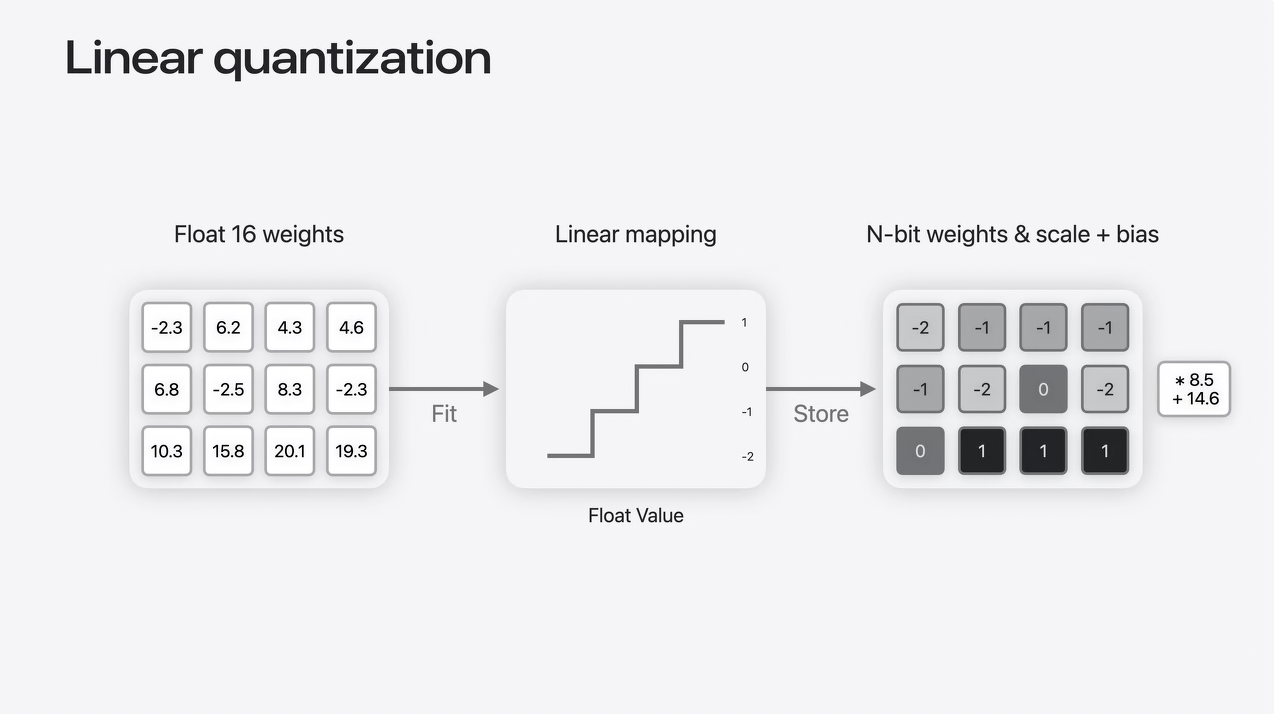
Linear quantization
2つ目の手法は量子化と呼ばれるものです。
量子化を行うには、浮動小数点数(Float)のウェイト値を整数の範囲に線形マップします。
整数のウェイトは、量子化パラメータとして知られるスケールとバイアスのペアとともに保存され、後で整数をフロートに戻すために使用できます。
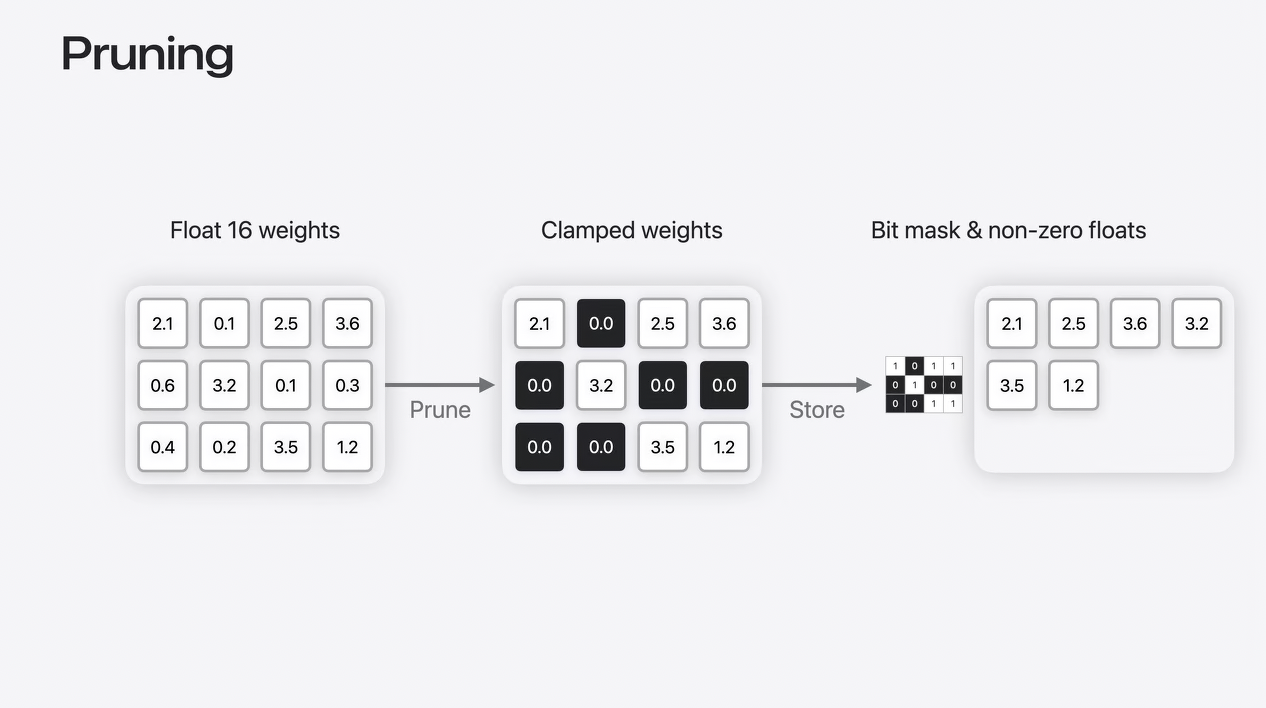
Pruning
3つ目のテクニックはプルーニングです。プルーニングは、モデルの重みをスパース表現で効率的に詰め込むのに役立ちます。
重み行列から始めて、最小の値を0に設定します。これで、ビットマスクと0以外の値だけを保存すればよくなります。
既存のテクニックは、多くのモデルでうまく機能しています。では、これらのテクニックのいくつかを大きなモデルに適用し、さらに圧縮するためにどのように拡張したかを見てみよう。
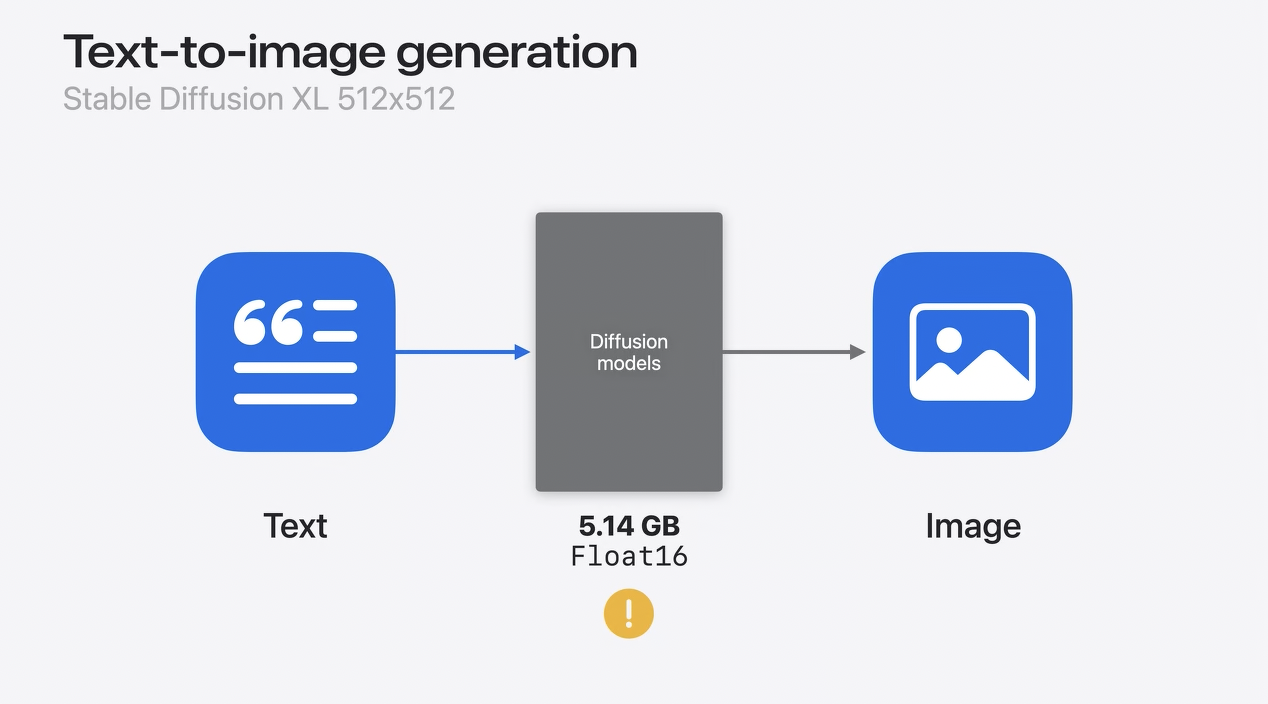
Text-to-image generation
安定拡散モデルの例です。これはプロンプトとして知られる自然言語の説明を受け取り、その説明に一致する画像を生成します。
変換してみると、一番大きなモデルのモデルサイズはFloat16の精度で5GBを超えていることがわかります。
これは当初、iPhoneやiPadで実行するには大きすぎ、このモデルをデプロイするには、圧縮する必要があります。

Palettization on Stable Diffusion XL
圧縮率を変えるためにビット数を柔軟に選択できるパレット化を試してみます。
例えば、8ビットのパレット化を適用すると、モデルのサイズをFloat16モデルの約半分にすることができます。私のMacでは、プロンプト「タキシードの猫、キャンバスに油絵」で素晴らしい画像を得ることができます。
しかし、iPhoneやiOSとの統合を考える前に、このモデルを2GB以下にしたい。6ビットならこの条件を満たすことができ、最終的にiPadでこのモデルを動かすことができます。
4ビットはどうですか?良い画像が得られなくなりました。つまり、モデルが正確でなくなったのです。
では、ここで何が起こっているのか?よりよく理解するためには、まずパレッタイズ表現を見直す必要があります。
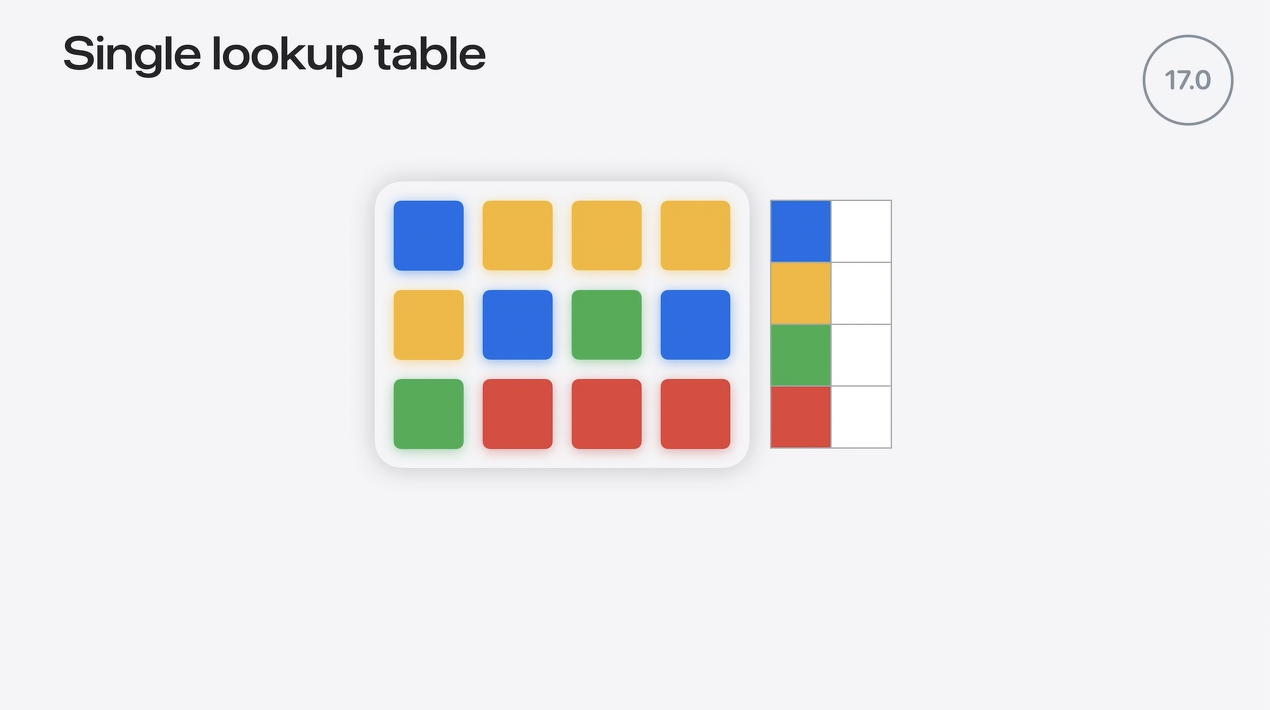
Single lookup table
iOS 17は、すべての値が単一のルックアップテーブルにクラスタ化され、テンソルごとのパレッタイズのみをサポートしていました。4ビット・パレタイズが使用される場合、テンソル全体にマップバックするクラスタ・セントロイドは16個しかありません。これは粒度が小さいため、大きな行列では潜在的なエラーが発生しやすくなります。
では、どのように粒度を上げるかを考えてみます。

Granularity
一歩下がって、機械学習の分野でよく使われる用語をいくつか説明します。
重みは行列で表すことができ、ここでは行列の行で出力チャンネルを、列で入力チャンネルを表しています。
テンソル全体に圧縮を適用することもできるし、各チャンネル・グループ、あるいは各チャンネルに個別に圧縮を適用することもできます。
それぞれの行を小さなブロックに分割し、サブチャンネルレベルで圧縮をかけることもできます。
図の左から右に向かって、粒度は徐々に大きくなっていきます。
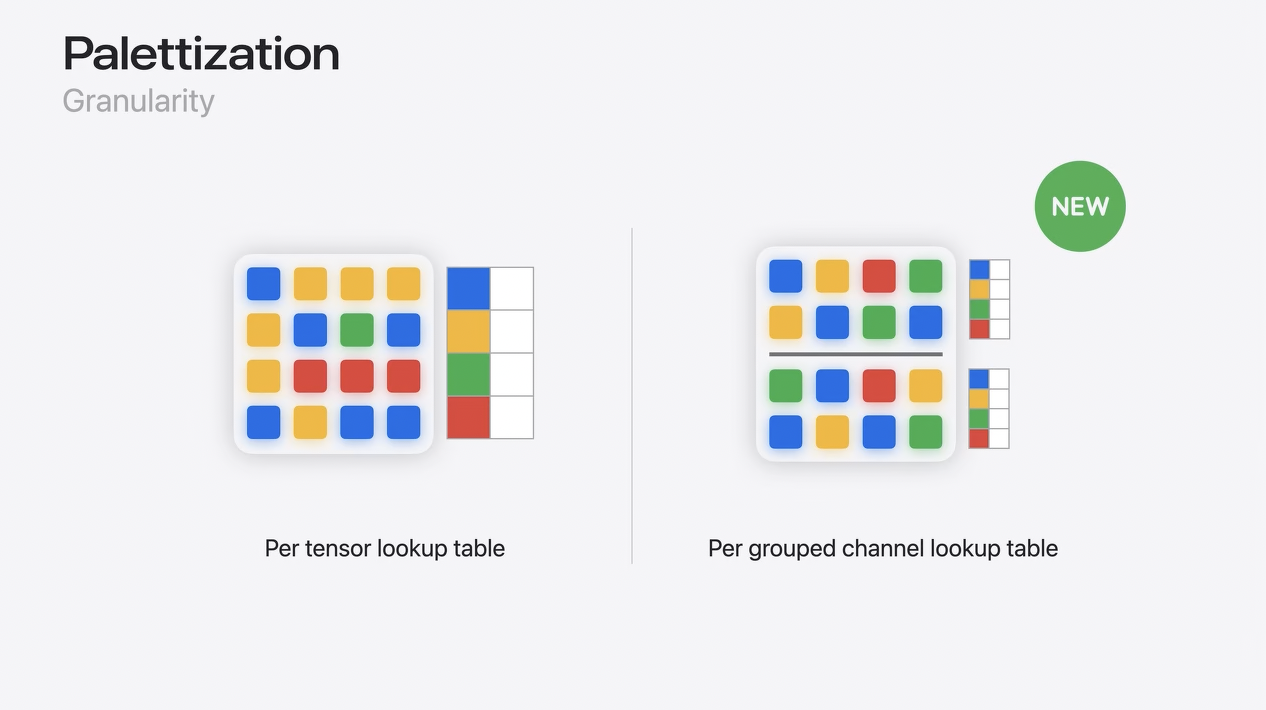
Palettization
Palettizationに話を戻すと、iOS 17ではフル・ウェイト・テンソルに1つのルックアップテーブルを割り当てることができましたが、iOS 18では複数のルックアップテーブルを格納できるようになりました。これにより、はるかに優れた精度を達成できます。
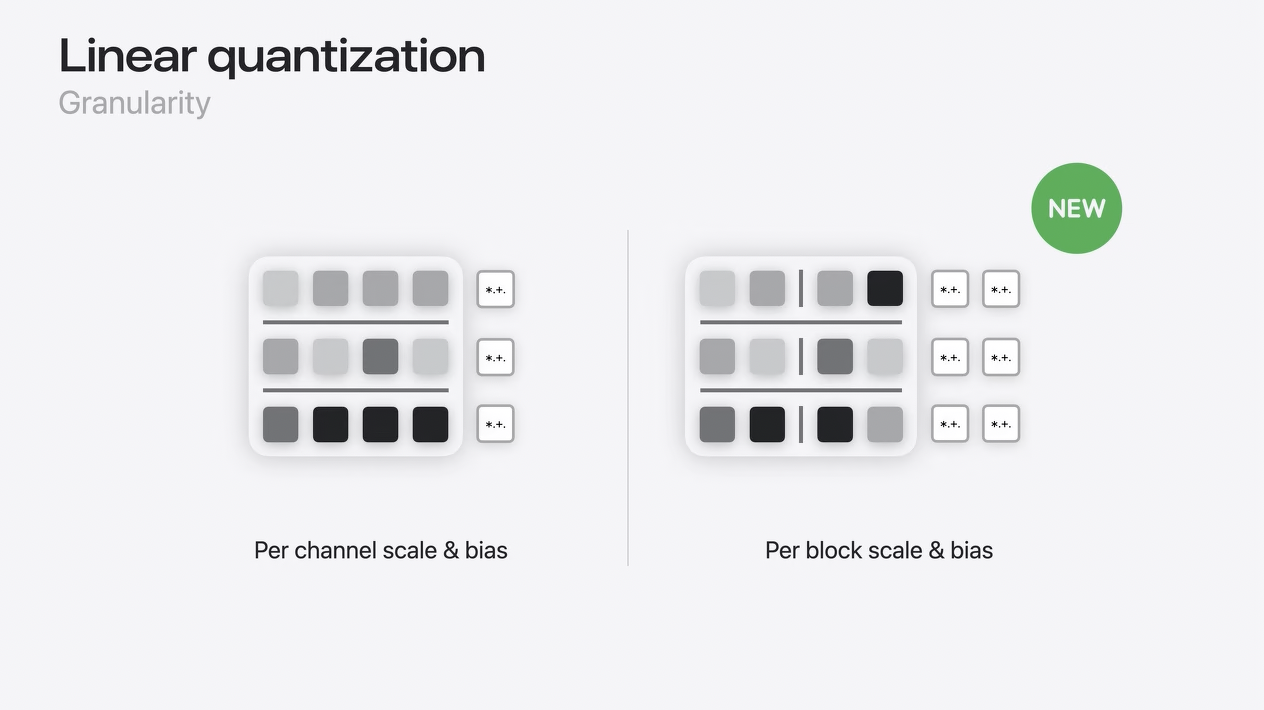
Linear quantization
線形量子化については、iOS 17ではチャンネルごとにスケールとバイアスを設定できましたが、iOS 18ではこれらの量子化パラメータをブロックごとに設定できるようになりました。
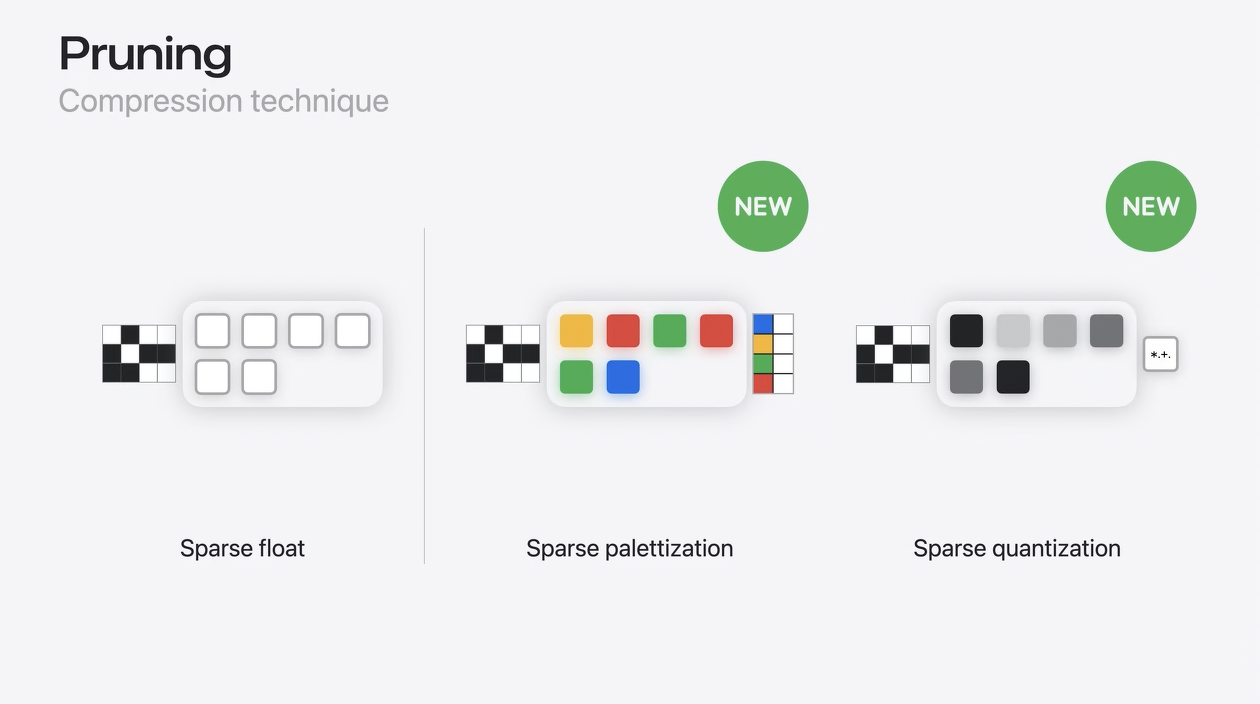
Pruning
プルーニング技術についても、さらに圧縮できるようになりました。以前は、密なウェイトがFloat精度の非ゼロ値にスパースされていました。
この浮動小数点の非ゼロ値は、Palettizationや量子化を使ってさらに圧縮することができます。
2つの異なる圧縮技術の特徴を同時に利用することができるようになり、スパースパレット化とスパース量子化が可能になったのです。

Palettization on Stable Diffusion XL
このモデルのパフォーマンスを見てみます。
group_size 16で、私のプロンプトにマッチする別の猫が見えます。この生成された画像は以前よりずっと良くなっています。
つまり、1.29GBから1.3GBへとサイズがごくわずかに増えただけで、精度のほとんどを取り戻すことができました。
この増加は、追加されたルックアップテーブルによって余分な容量が少し増えたためです。
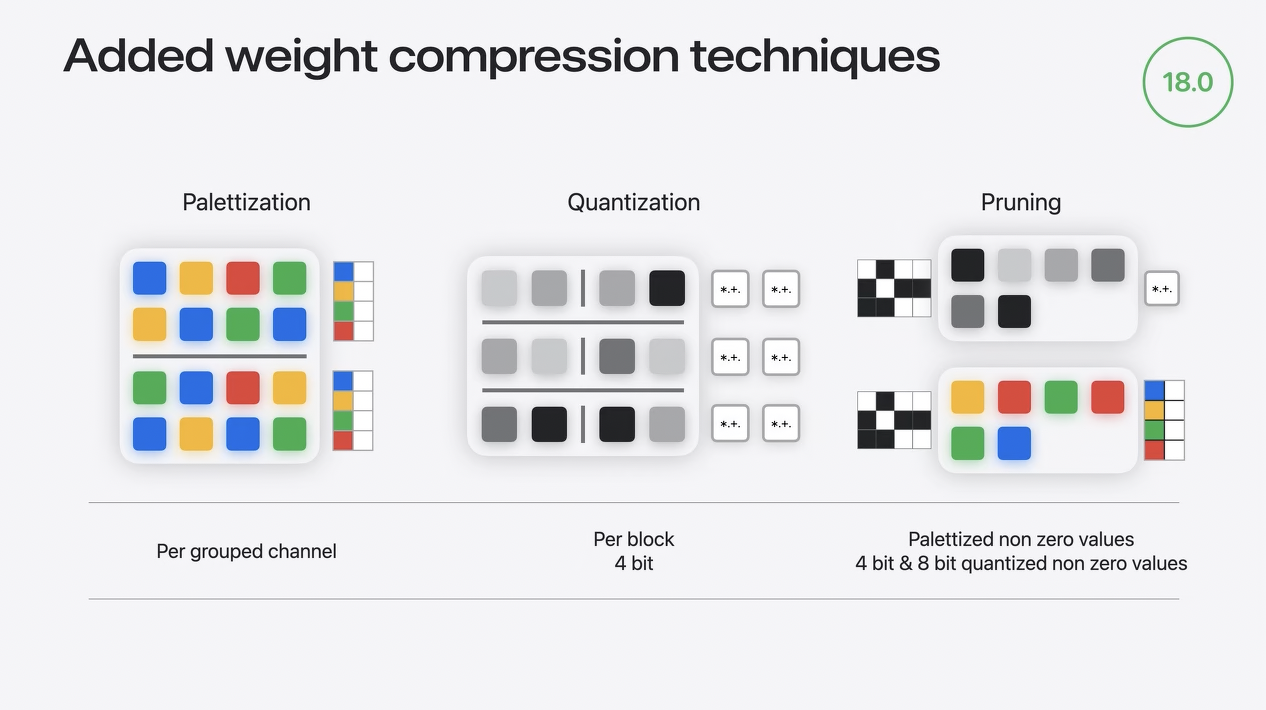
Added weight compression techniques
まとめると、iOS 18では、グループ化されたチャンネルごとのパレタイズは、複数のルックアップテーブルを持つことによって粒度を増加させます。
これはニューラル・エンジンを搭載したApple Siliconで輝きを放ちます。ブロックごとの量子化に加えて、8ビットから4ビット量子化もサポートするようになりました。
このモードは特にMacのGPUに最適化されています。
最後に、スパース性を他の圧縮モードと組み合わせることができるようになりました。
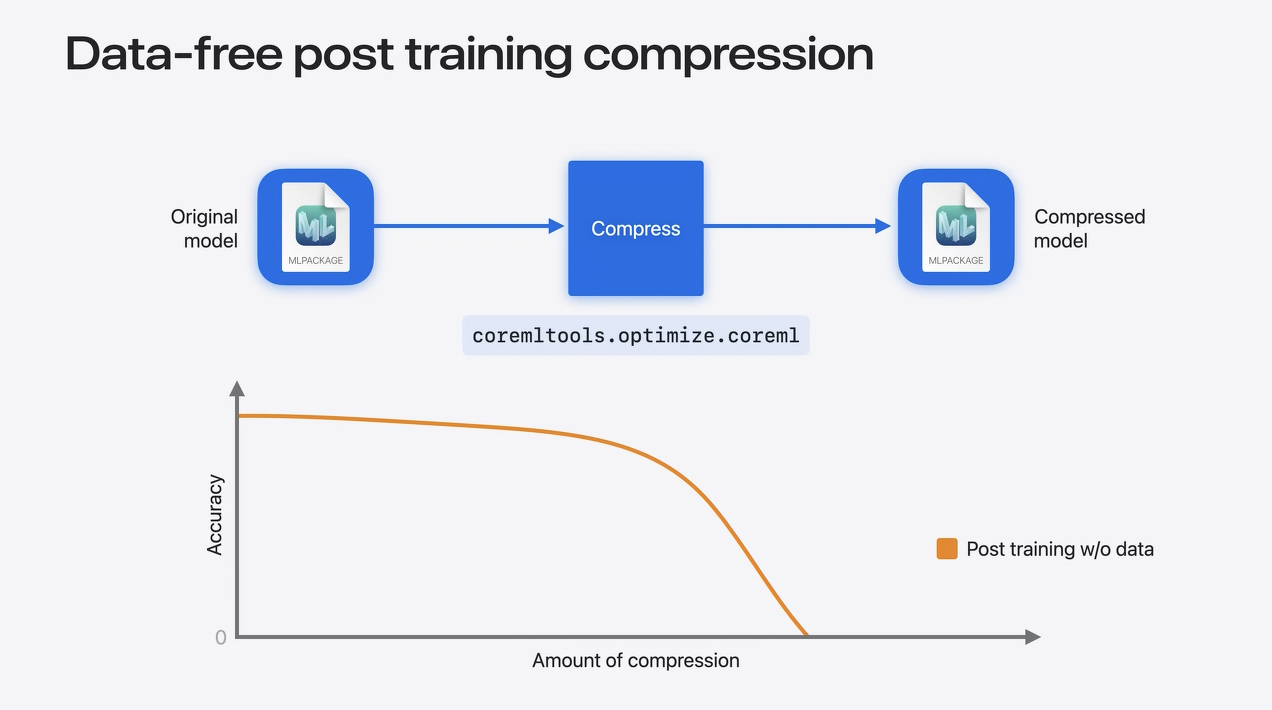
Data-free post training compression
モデル圧縮について結論付ける前に、圧縮ワークフローについて説明します。
これまでのところ、圧縮に使用してきたワークフローは、ポストトレーニングアプローチです。これは事前にトレーニングされたCore MLモデルから始まり、非常に便利な方法でデータなしで圧縮されます。
しかし、このデータフリーのワークフローは、精度と圧縮量の最適なトレードオフをもたらさないかもしれません。圧縮率が高くなると、精度が急速に低下します。
これを回避する1つの方法は、学習時間圧縮を使用することです。
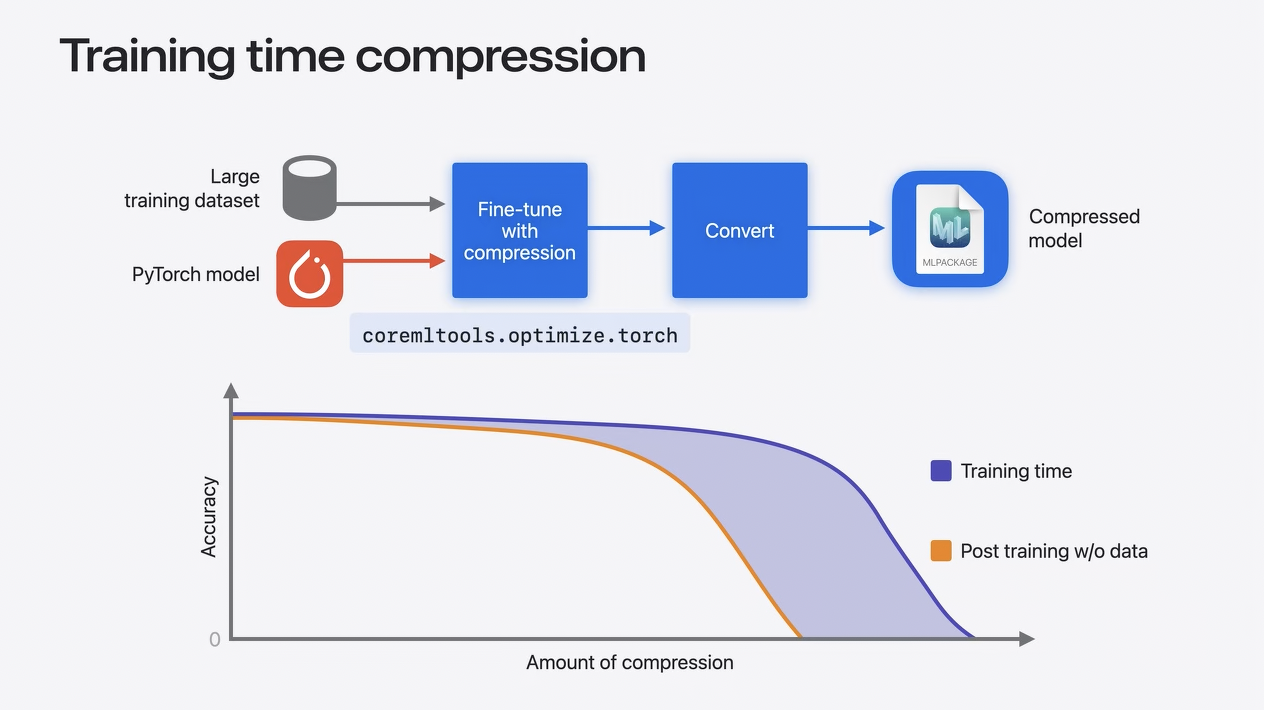
Training time compression
重みを圧縮しながら、PyTorchモデルを学習データで微調整することができます。そしてそれをCore ML形式に変換します。
これにより、より正確なモデルを得ることができますが、このプロセスは時間がかかり、大規模なモデルではデータを消費します。

Post training compression with calibration data
そこで、新しいワークフローをご紹介します。それは、キャリブレーションデータを使ったポストトレーニング圧縮です。
これは、データフリーアプローチとファインチューニングアプローチの中間のトレードオフを提供します。
この場合、モデル圧縮のキャリブレーションに必要なデータ量は限られています。微調整はまったく必要ないため、セットアップが簡単で、時間もかかりません。
今年coremltools.optimizeに導入された新しいAPIを使えば、このワークフローを非常に簡単に実行できます。

Sparse palettization on Stable Diffusion XL
スパースモデルをCore ML形式に変換することもできますし、スパースパレタイゼーションが可能なので、プルーニングの後にパレタイゼーションを行い、さらに圧縮することもできます。
スパースメタデータ情報を渡すために、前回取得したスパースモデルを使用します。ここでも、必要なモジュールをインポートし、パレット化の設定を行います。ここでは、4ビット粒度を "per_grouped_channel "に、group_sizeを16に設定しました。
PostTrainingPalettizerオブジェクトを作成し、palettizer.compressでsparse_palettized_modelを取得します。このPyTorchモデルはシームレスにCore ML形式に変換することもできます。
40%のスパース性を適用した後、安定した拡散モデルのサイズはさらに1.1GBに縮小されます。
データフリーのポストトレーニング圧縮では、モデルはノイズ出力しかできませんが、データキャリブレーションワークフローでは、モデルは別の猫画像も生成できます。
キャリブレーションに基づくワークフローはうまく機能しています。

Core ML Tools 8
まとめると、Core ML Tools 8では、新しい圧縮表現を試すことができます。
また、キャリブレーションデータを使用する新しい圧縮ワークフローも使用できます。